Upload a dataset
Drop in a file and it becomes a dataset your agents can query immediately:- Tabular — CSV, Excel (
.xlsx,.xls) - Documents — PDF, Word, PowerPoint, Markdown, text, JSON, and more
What Erdo works out on upload
For tabular data, the analysis goes well beyond “read the first row as headers”:- Schema & types — every column is profiled and typed (number, date, text, boolean), with null counts, distinct-value counts, and ranges.
- Messy real-world files — Erdo finds the actual header row in
report-style exports that start with titles, logos, or blank rows, and merges
multi-row headers (e.g.
Revenue / Q1,Revenue / Q2) into clean column names. - Number formats — thousands separators, currency symbols, percentages, and
accounting-style negatives like
(1,234)are recognised as numbers, not text. - Currencies — an ambiguous
$column is resolved using nearby country/region columns where possible, so totals aren’t silently mixed. - Time series — date columns get their range and gaps detected, so an agent knows when a month is missing before it reports a trend.
This upfront analysis is why an agent can answer a question about a freshly
uploaded file straight away — it already knows the columns, types, and quirks.
Connect a source
A connector is an authorized link to an external tool or system — your database (PostgreSQL, Snowflake, BigQuery, ClickHouse), Google Workspace, Slack, Shopify, Stripe, GitHub, and many others. Connecting one lets agents read from it and, with your approval, act in it.Sign in and authorize
Authorize through the provider. Connections are per user and encrypted —
each person connects their own accounts.
Use it in a thread
Agents can now pull from the source. Sources that sync (like a database or a
store) turn their tables into queryable datasets,
schema-analyzed just like an uploaded file.
Dataset vs. connector: a connector is the source (the authorized link); a
dataset is the queryable data that lands in Erdo. One connector can produce many
datasets. In day-to-day use you’ll mostly think in terms of “connect Shopify” and
then “query my Shopify orders.”
Connect a custom API
If a tool isn’t in the gallery but has an API, point Erdo at its API docs and an agent will generate a client for it. You then connect with your API key and query it like any other source — no code to write yourself.Bring your semantic layer
If you’ve already defined your business model in dbt, LookML (Looker), Power BI, or Tableau, you don’t have to redefine it in Erdo. Import the model and Erdo turns it into knowledge your agents share:- Metrics — measures and their formulas (revenue, ROAS, CAC) become canonical definitions, so every agent computes them your way.
- Entities & dimensions — your business objects (campaigns, orders, customers) and their fields, mapped back to the tables they live in.
- Relationships — join conditions between models are preserved, so agents know how your tables connect.
- Row-level security — access filters from LookML carry over as mandatory query constraints, so agents respect the same boundaries your BI tool does.
How agents query your data
You never write the query — you describe what you want, and the agent picks the right path:- SQL for direct questions over a dataset or synced table — fast filtering, joins, and aggregation. Results come back as a new dataset you can query again.
- Python for multi-step analysis, statistics, and API-only sources (like Google Analytics or ad platforms) where a single SQL query won’t do.
Getting answers right
This is where Erdo is different. An agent doesn’t just run a query and report whatever comes back — it digs in and checks its own work before showing you a result: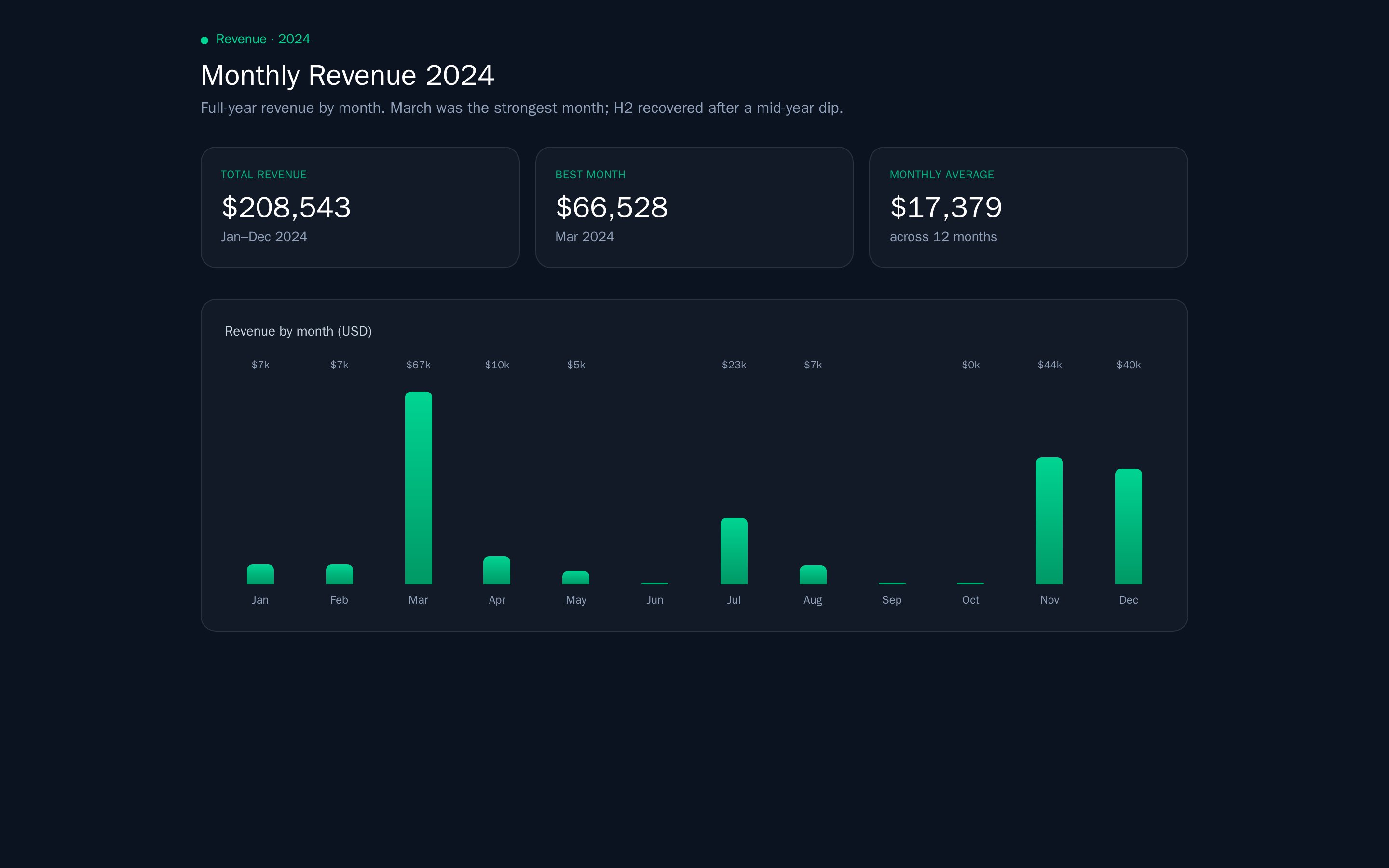
- Does this answer the question? A separate quality check confirms the analysis addresses what you actually asked — the right metric, the right grain, the right time window — not a plausible-looking proxy.
- Trust the data, not the assumption. If the data disproves the obvious approach (a join key that’s empty, a column that doesn’t exist, a filter that returns nothing), the agent adapts and re-runs instead of forcing the original plan.
- Catch the silent failures. Empty result sets, all-zero or all-null columns, suspiciously small counts, and contradictory totals are flagged and investigated rather than presented as fact.
- Decision-quality verdicts. For “did this work?” questions — experiments, launches, funnels — Erdo insists on comparable before/after windows and a real primary outcome, so a rise in vanity activity doesn’t get reported as success.
- Validated refreshes. When a synced dataset refreshes, Erdo checks invariants like key uniqueness so a broken sync doesn’t quietly corrupt later answers.